




 2022-05-20
2022-05-20
 点击量:
点击量:
人体姿态估计是人工智能提供的一种流行的解决方案;它是用来确定的位置和方向的人体图像包含一个人。
在健身中应用姿势估计的例子有Kaia, VAI健身教练,Ally apps,或者Millie Fit设备。
在计算机视觉和自然语言处理算法的支持下,这些技术引导终端用户通过一系列训练并给出实时反馈。
通过力量举重和蹲举练习的例子了解基于ai的健身应用程序的失败案例。
该区域可分为二维姿态估计和三维姿态估计。虽然二维位姿估计的精度已经达到了可接受的水平,但三维位姿估计仍需要更多的工作,直到产生更精确的模型。
健身是当今的一种趋势。健康创意报告显示,健身行业的收入每年都在以8.7%的速度增长,而健身应用也未能幸免。
有很多技术可以帮助改善你的身体的例子——从跟踪运动活动到调整营养。问题是,与人类教练相比,这些应用程序在提高体育锻炼成绩方面能有多好?
人工智能(Al,用于自动执行各种任务的一组高级方法、工具和算法的总称)多年来已经几乎侵入了业务的所有功能领域。姿态估计是AI提供的最流行的解决方案之一;它是用来确定的位置和方向的人体图像包含一个人。不出所料,这样一个有用的工具已经发现了许多用例,例如,它可以用于阿凡达动画的人工现实,无标记的动作捕捉,工人的姿态分析,以及更多。
随着人体姿态估计技术的到来,基于人工智能的私人教练app已经充斥了健身技术市场。在健身中应用姿势估计的例子有Kaia, VAI健身教练,Ally apps,或者Millie Fit设备。在计算机视觉、人体姿态估计和自然语言处理算法的支持下,这些技术可以引导终端用户进行大量训练,并给出实时反馈。
为了了解现代健身应用程序是否真的能帮助人们正确地进行体育锻炼,让我们回顾一下基于人体姿态评估的应用程序是如何工作的。
任何人类造成估计的核心应用程序是一个姿势估计算法,其接收的图像作为输入和输出的坐标对人体特定的要点或地标(XY坐标2 d姿势估计或XYZ三维坐标构成估计)。现代的姿态估计算法几乎完全基于带有沙漏结构或其变体的卷积神经网络(见下图)。这样的网络由两个主要部分组成:一个卷积编码器,它将输入图像压缩成所谓的潜表示,和译码器,它从潜表示构造N个热图,其中N是搜索的关键点的数量。
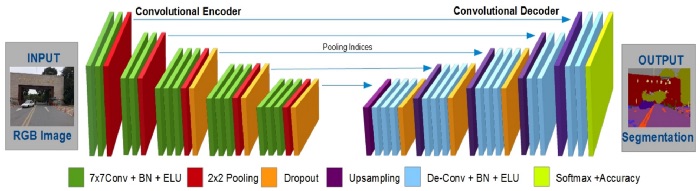
作为输出产生的单个热图是与输入具有相同分辨率的单通道图像。每个像素都有一个包含目标关键点的概率,用0到1之间的值表示。

热图得到后,计算关键点的坐标就像找到关键点概率高的每个区域的质心一样简单。
然而,问题有时会变得复杂,因为框架可能包含不止一个人。当这种情况发生时,就很难理解哪些关键点属于哪些人,因此需要额外的后处理。这种情况称为多人姿态估计,可以用多种方法处理。例如,可以使用一个对象检测模型(例如单镜头检测- SSD, Mask R-CNN等)来检测一个人周围的包围框,然后在被检测框内运行姿态估计模型。另一种方法是使用快速贪婪解码算法,连接最近的关键点基于运动学的人图。谷歌在PoseNet模型中采用了这种方法。
通常情况下,基于人工智能的健身应用应该通过装备有摄像头的设备来使用,摄像头可以拍摄720p和60fps的视频,以便在运动过程中捕捉更多帧。基于人体姿态估计的app常用算法如下:
1、当用户开始使用健身app时,摄像头会捕捉用户在运动过程中的动作并记录下来。
2、在人体姿态估计模型的帮助下,录制的视频被分割成单独的帧,检测用户身体上的关键点,在2D或3D维度上形成虚拟的“骨架”。
3、通过基于几何的规则或其他方法对虚拟“骨架”进行分析,找出练习中出现的错误。
4、用户会收到错误的描述以及如何改正错误的建议。
人类姿态估计的库和工具
由于人体姿态估计对于创建各种系统(监视系统中可疑活动的识别、交互式舞蹈助手、增强现实等)是一个有用的工具,所以在创建需要姿态估计的应用程序时,一些能够帮助加速开发过程的工具自然出现了。让我们简要讨论一些可用的选项。
青瞳视觉编译,其目的是为了将更好的内容分享给更多人,版权依旧归原作者所有。若有涉及侵权请予以告知,我们会尽快在24小时内删除相关内容,谢谢。
-
 美国陪审团称迪士尼欠60万美元的动作捕捉版权审判
美国陪审团称迪士尼欠60万美元的动作捕捉版权审判里尔登指责迪士尼在《美女与野兽》中滥用技术。诉讼称,迪士尼使用了“被盗”版本的面部捕捉软件美国加州一个联邦陪审团周四裁定,迪士尼应为其在2017年翻拍真人版《美女与野兽》时使用了另一家公司的动作捕捉技术,
2023-12-25 行业新闻 -
 《杀出重围》主角亚当·詹森的签名配音演员也想做动作捕捉
《杀出重围》主角亚当·詹森的签名配音演员也想做动作捕捉By Ted Litchfield 在《人类革命》中。伊莱亚斯·图菲西斯完成了《人类分裂》的全部表演。不要让网上的软件告诉你不同的说法:5英尺11英寸和6英尺1英寸之间的差距并没有那么大。然而,演员Elias Toufexis最近
2023-11-14 行业新闻 -
 《博德之门3》导演解释为什么每个NPC都是Mo-Capped
《博德之门3》导演解释为什么每个NPC都是Mo-Capped8月25日,动作捕捉导演阿利奥娜·巴拉诺瓦在推特上解释说,如果没有近数百名演员勤奋的动作捕捉表演,拉里安工作室的《龙与地下城》角色扮演游戏《博德之门3》就不会有今天。“对于我们录制的几乎所有对话,我们
2023-10-23 行业新闻